Fine-Tuning GPT-3 to Generate Full Stack App Ideas

My name is Justin! 👋 I am a hobbyist and freelancing Full Stack Developer using Next.js & TypeScript who designs games sometimes. 😎
Currently: Learning anything and everything I can about supporting scalable server applications and gorgeous frontends!
💼 Over 8 years working in IT
💻 Full Stack (Next.js/Typescript/MongoDB)
🎓 B.S. in Cybersecurity & Information Assurance
🎗️ Multiple IT certifications and skillsets
🕹️ Founded a local game design studio in Dallas, TX
I'm open to full stack, fully remote positions! Please get in contact.
Hey all! 🤖
Much like most of the developers out there looking for new technology that is rapidly growing, and with the rise of recent art-based machine learning (ML) engines like Stable Diffusion and DALL-E/DALL-E 2 making rounds in the news, procedurally generated and ML generated content is being utilized more and more by companies and consumers alike.
Today, I just wanted to make a quick post on what fine-tuning an ML model made for GPT-3 looks like, and what that kind of process looks like from beginning to end on generated customized specific output. Most of the documentation online is based around Python, so just to preface: this article will be focused on fine-tuning GPT-3 with JavaScript & Node.js. 🚀
Customizing Application Models
GPT-3 is the most recent iteration of what is known as an Autoregressive Language Model, which is just a fancy way of saying it processes creating future values (in this case natural language) based on previous ones with statistical analysis. The foundation of this model is built on what's called a Transformer if you wanted information on the technical architecture, but I won't go into that detail here.
When created, GPT-3 was trained with over 45TB of data from various datasets, runs on around 175 billion ML parameters, and can hold almost Turing-complete conversations of high-intelligence and accuracy strictly using it's default training data. Different 'variations' of the state and accuracy of GPT-3 (think of them like software release versions) are known as models. The various models OpenAI (the collective behind GPT-3) has trained continue to improve every couple of months. With every new iteration or completely new model, the quality and performance of the generated output improves overall. For this post, we're using text-davinci-002 as the current base training model.
Today though, we need to train and wrangle GPT-3 to parse information customized to what we feed it. In this instance, we need to generate names and descriptions for full stack SaaS applications! More explicitly, we need to generate SaaS ideas in the Marketing 📈 sector for some potential clients. We don't need detailed spec sheets, but just a blurb of an idea we can brainstorm later. Sometimes thinking about what to create can be half the battle! This newly compiled output we need to generate will be used to 'present to the CEO by Monday morning!! 🤯' (Just a little example scenario)
This process of tuning GPT-3's regression model is actually very straight forward and doesn't require intense understanding of machine learning or statistical analysis. It's simply a plug-and-play feature on feeding it data, having it learn directly from that dataset and create a fine-tuned model for us, then using that model in a future setting to generate the specific data we need. Though keep in mind, the pricing structure for running data through the fine-tune process is different than making standard queries and may vary.
Locating & Loading Training Data
Now I realize I spent the previous paragraphs explaining the large amount of data and info GPT-3 has been trained on, but this is still a learning technology; it's not omniscient nor smart to begin with. When we query GPT-3 directly using their Playground, we can start by asking it a simple question without any pre-trained data:
Create a list of marketing SaaS application names and descriptions using the following example:
Stock AI - Get Stock Images Generated by AI + In-built blogpost image generator.
Here are the results that are returned:
1. AI Stock - Generate Stock Images with AI
2. Blogpost Image Generator - Generate Images for Blogposts
3. SaaS Stock - Get Stock Images from SaaS
4. Image Stocker - Store and Generate Images for Stock
As you can see, the output is not that good... Granted, we did only supply one example. Let's see what happens when we supply more than one example based on different products.
Create a list of marketing unique SaaS application names and descriptions using the following examples:
Stock AI - Get Stock Images Generated by AI + In-built blogpost image generator
Mouseflow - A behavioural Analytics tool to work better with your CMS.
Pukket - Social Media Management App focused on Local SMBs.
1. Sprout - Social Media Management App
2. Hootsuite - Social Media Management App
3. Buffer - Social Media Management App
4. CoSchedule - Social Media Management App
Again the output is not great, and I believe we may have confused the model even more? Instead of producing unique outputs (products that don't exist), it seems to just be listing existing SaaS products and repeating data at this point. (Note: the Playground is using default model parameters)
To change this, we need to load our model with custom datasets to train it to produce better output! 🏋️ Where are going to find this data, you ask? Well, it can come from a multitude of places. This data can be generated by a coffee-fueled intern, from a public dataset, or shamelessly plucked from Reddit. Thank you, u/lazymentors, for taking the time to write out this long post containing the perfect amount of data to run a small training set for us!
In terms of accuracy, this may not be a large enough dataset to be honest. Most training sets contains hundreds or thousands of rows of data. While around hundred-ish examples won't provide a pristine output for us, it can give us a starting point.
Writing Code
Let's start by making a empty directory and initializing our package manager to install what is needed, we'll be using Yarn for this tutorial:
mkdir gptfinetuning && cd gptfinetuning
yarn init
yarn add openai dotenv
Now let's go ahead and navigate to the OpenAI website, sign in or create an account. Verify that you have enough credits to create API requests! I believe free accounts have a trial credit applied to their account to make free quests, but I can't remember, unfortunately, as I do pay for the API currently.
Click on your name in the top right-hand corner and select the "View API Keys" button. This will take you to your secret API keys page. Make sure to keep these a secret to protect your API usage! Make sure you either create a new secret key, or copy one that you already have generated. From there, head back to the project directory and we're going to create our local .env file to store our API key. You can create the file in the root of the gptfinetuning folder, and within it, create the following field:
OPENAI_API_KEY = [YOUR API KEY]
Save it and now you're ready to start making requests via the API!
Create a new file named index.js in the root directory. Create an asynchronous function named main() and start by calling the openai library and making a test request using their API.
const fs = require('fs');
require('dotenv').config();
const { Configuration, OpenAIApi } = require('openai');
const main = async () => {
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.createCompletion({
model: 'text-davinci-002',
prompt: 'What are some things to keep in mind when building a SaaS application?',
temperature: 0.7,
max_tokens: 256,
});
console.log(response.data.choices);
};
main();
We will filter the entire response to response.data.choices which will give us only the necessary info and will get rid of all the filler information that is not needed for this article.
In order to test our new script, let's go ahead and inside of the package.json, we'll add a new scripts field to point to our index file, standard stuff:
"scripts": {
"dev": "node index.js"
}
yarn dev
After some amount of time, we get a response if all is well! You'll know rather quickly if you messed up or if your API key is invalid and will receive an error. Here's the response we received:
[
{
text: '\n' +
'\n' +
'Some things to keep in mind when building a SaaS application include:\n' +
'\n' +
'-Making sure the application is scalable\n' +
'-Ensuring the application is available on all devices\n' +
'-Making sure the application is secure\n' +
'-Ensuring the application is easy to use',
index: 0,
logprobs: null,
finish_reason: 'stop'
}
]
Done in 3.52s.
Now that we can create some basic requests and receive some data, let's now shift our focus to training GPT-3 to accept our custom data.
Validating & Training Data
Before we can give our dataset to GPT-3, we need to prepare it and make sure it's in an acceptable format to processed. There are a couple of ways to go about this, and OpenAI also offers tools that allow you to validate your data, with the application giving you recommendations on how to fix the dataset if it messed up and will even attempt to automatically fix them for you if it can. Note: you will need python installed to access the CLI tools. I'm sure there's a way to do it via the REST API but I haven't looked into it.
Here is a quick example of the format of the training data needed:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
So after fixing and correcting the dataset we received from the Reddit, we're left with a file that looks like this, edited for brevity:
{"prompt": "Generate a SaaS Name and description: ->", "completion": " SaaS Name: Pukket, Description: Social Media Management App focused on Local SMBs.\n###"}
{"prompt": "Generate a SaaS Name and description: ->", "completion": " SaaS Name: Stock AI, Description: Get Stock Images Generated by AI + In-built blogpost image generator.\n###"}
{"prompt": "Generate a SaaS Name and description: ->", "completion": " SaaS Name: Rewardful, Description: Build Your own affiliate program to scale your business.\n###"}
{"prompt": "Generate a SaaS Name and description: ->", "completion": " SaaS Name: PageFlow, Description: Storytelling Tool to generate content in English & German.\n###"}
{"prompt": "Generate a SaaS Name and description: ->", "completion": " SaaS Name: Arcade Software, Description: To create Interactive Product Demos for Landing Pages.\n###"}
{"prompt": "Generate a SaaS Name and description: ->", "completion": " SaaS Name: Lanva.io, Description: Turn Your Long form webinars and streams into Tiktok Videos.\n###"}
Here is the full training dataset. It's unfortunately not that long. This will actually affect quality of the generations later, but it's the most we have access to for now.
You may notice a couple of interesting tidbits with the validated training data. There are some minor fixes you will have to perform to the data manually in order for it to be accepted.
- The
->symbol at the end of thepromptfield is required by OpenAI to tell the model to begin the completion data after this symbol. - In order to assist with tokenization, a white space is required at the start of every
completionfield. - At the end of each
completionfield, the characters\n###inform the model to start a new line and interpret the###as the end of completion data.
While all the prompts are the same, the dataset should still link the SaaS name and description together when we request some generated data!
Requesting a Response
Our training data is all setup! Let's actually train a new model to tell GPT-3 what kind of output we're expecting. To start, we need to give OpenAI our training data and upload it to their servers. I recommend this being a two-step process, with separate functions, but that's my personal opinion. It can quickly get confusing which models are being used.
In the index.js file that we created earlier, we'll insert the following code:
const uploadFile = await openai.createFile(
fs.createReadStream('data/training.jsonl'),
'fine-tune'
);
const fineTuneResponse = await openai.createFineTune({
training_file: uploadFile.data.id,
model: 'davinci',
suffix: 'uniquesaas',
});
console.log(fineTuneResponse);
We'll upload our data/training.jsonl file to the OpenAI servers with the createFile() function, that is basically a POST request to their endpoint. You should receive an HTTP 200 status code from performing that action in the console's log.
Finding out the name of your newly fine-tuned model can be found two ways. I find one of those ways being significantly easier than the other. For the easy way, give the fine-tune job some time to process on their servers. (For me, about 5-10 minutes) The model is not created immediately, rather it's queued and once completed, will be available to use. If you navigate to OpenAI's main dashboard page, find your name in the top right-hand corner, and select Manage Account, under the Usage tab, and under the Daily usage breakdown, you will see two sections detailing the model usage requests and fine-tune training requests for that day. From there, if your fine-tuned model was accepted, it's output will be displayed here along with it's model name, which is important for us to have.
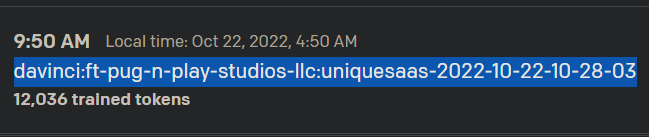
The second way to find this data is programatically. You can run await openai.listModels() to provide you an entire list of all models that are available to your API. This includes all the default models created by the OpenAI team as well as all the models you've ever created to be fine-tuned. You'll have to manually sift through your models to find the one you need if you go this route. I highly recommend just going through the website, it takes like two seconds. If you must, this is another way.
⚠️ Important to Note: Once the fine-tuned model has been created and uploaded, you no longer need to run the createFineTune() function, as fine-tuning models are very costly (IRL $$$) to train!
Querying GPT-3
Taking our new model, let's create a new function that will finally query GPT-3 and request new SaaS ideas! Using the same code from our test function we ran earlier to get the project communicating with the server, we can just replace a few variables to get us where we need to go:
const response = await openai.createCompletion({
model: 'davinci:ft-pug-n-play-studios-llc-2022-10-22-10-04-42',
prompt: 'Generate 8 unique SaaS products with names and descriptions:',
stop: '###',
temperature: 1,
max_tokens: 256,
});
console.log(response.data.choices);
- In the
modelfield, this is that fancy fine-tuned model name we were talking about earlier that you can find from your OpenAI usage information in your account settings. - The
promptis what you'd like to query the server for, like you would normally use GPT-3. - You must define the custom
stopterminator during your query. This can be any string of characters, but it is recommended that the sequence is unique and not show up anywhere else in your dataset. temperaturedefines how risky the model is in terms of generating output. This is great to edit if you'd like to try new suggestions.max_tokensdefines the token limit on the generated output.
Conclusion
Thank you for staying with me for this long! And I hope you learned something! I'm going to share my generated data below, but if you used my article to help you with your project, please just a comment below and let me know what you're working on!
With that, let's take a look at some suggestions from GPT-3:
SaaS Name: Tool Hunter
Description: To Find the best Beta Software products and Get the Access to them from one place.
SaaS Name: Taskade
Description: A minimalistic alternative multi-tasking app for Mac.
SaaS Name: Ideate+
Description: A Content Analytics platform to help content creators with audience & engagement insights.
SaaS Name: Asketi
Description: A HR and Recruitment tool that helps you find and approach candidates for your job roles.
SaaS Name: Paperform
Description: A simple online form builder tool that helps you collect feedbacks from your website visitors easily.
SaaS Name: Smartlook
Description: A video recording tool for your website that helps you create Product Demos and explainer videos.
SaaS Name: Polldaddy
Description: A survey tool where you can create and distribute surveys for your audience to understand their behavior.
SaaS Name: Webflow
Description: A web design tool where you can create responsive websites without coding.
And there you go. We can report to our "CEO" on Monday that we have 8 new project ideas we can pitch to our clients. 😎
Of course, the training data we used did not contain a lot of entries, and didn't seem to adhere to strictly marketing products as well, so we don't have the most high-quality responses. If the model can be expanded to include 300-400 examples to start, with improved completion fields, generated content should improve. There is also no guarantee that some of these ideas (names namely) aren't already taken and GPT-3 is just filling in the gaps, regardless if we specify them be unique or not.
I did also have to run the query a couple of times, as the first couple of generations did not understand the prompt well enough, or did not adhere to the style of completion output.
I hope you all enjoyed this article! Please leave some comments on if you'd like to see more of this kind of content, or what you thought of the piece! Thanks!