Designing Squrl 🐿️, an End-to-End Encrypted URL Shortening SaaS

My name is Justin! 👋 I am a hobbyist and freelancing Full Stack Developer using Next.js & TypeScript who designs games sometimes. 😎
Currently: Learning anything and everything I can about supporting scalable server applications and gorgeous frontends!
💼 Over 8 years working in IT
💻 Full Stack (Next.js/Typescript/MongoDB)
🎓 B.S. in Cybersecurity & Information Assurance
🎗️ Multiple IT certifications and skillsets
🕹️ Founded a local game design studio in Dallas, TX
I'm open to full stack, fully remote positions! Please get in contact.
Editor's Note: This project was completed almost a year ago and was mainly my first feature complete full stack application that I designed and developed from beginning to end.
It was practice for my university level knowledge in cybersecurity. Unfortunately due to costs and little demand, a demo is not available. 😢
The GitHub repository, on the other hand, lays everything out in great detail!
Over the past couple of years — and since I’ve began this arduous journey into programming; namely full-stack development — I’ve wanted to put my knowledge and my programming ‘prowess’ to the test. I wanted to make something with my own two hands that would be beneficial to the community and could potentially fix some issues that users are experiencing. I didn’t just want to make another to-do list or calculator app. On the road to my first potential full-stack interview, I needed to fill my portfolio with some projects that are worth talking about or bringing up to a prospective employer.
Many moons ago, I wanted to be a security analyst instead of a software engineer; or at least attempt to work in any kind of information security sector. I actually ended up attending university and getting my degree in Cybersecurity and Information Assurance while picking up a couple of infosec related industry standard certifications along the way. Now that I’ve graduated, it seems that I’ve gone in a completely different direction than where I wanted to be when I was getting my degree, which isn’t a bad thing per se, but I would just like to use my degree for something nice. When I was brainstorming for a project that would use a portfolio showcase, I thought it would be natural to make one of my projects dedicated to my path of education. It certainly doesn’t seem like I’m going to use it anywhere else! (For now…) So that’s where this leads us: what is Squrl?
Why Would the Internet Need Another URL Shortener?
Squrl stands for ‘Secure, Quick URL’, a URL shortening and E2EE service created to facilitate a privacy problem within the current services that offer URL shortening: bit.ly, shorturl, tinyurl, etc., among other major players within the game. Each of these services offer a couple of ‘solutions’ to URL shortening that, in my opinion, may be an overreach in terms of the problem it is trying to tackle: they all log large points of data and information to create ‘analytics’ and ‘click counts’ for your links as a ploy to gather marketing for engagement within certain businesses. Each of these links or redirections contain large swaths of personally identifiable information that exposes all kinds of private data to others who are willing to put in the effort to find it.
In 2016, two security researchers discovered that just by openly scanning and brute-forcing the available URL tokens used by OneDrive and Google Drive, they could stumble upon live and openly editable documents containing private information. It is very apparent that simply because a URL seemingly looks like it may be hard to find online amongst the sea of indexed pages with a randomized URL, that is not always the case. Some people are trusting their life’s most personal documents to these kinds of public links. Chris Dale wrote a great article for the SANS Institute about what kinds of personal and dangerous information openly available shortened URLs can generally include.
So what does this mean? People are blindly trusting marketing companies with protecting them and the data they openly share. Squrl aims to alleviate some pain regarding this issue.
Technicals on Secure Development
Creating URL shortening services are not relatively hard projects to accomplish if you wanted to give it a go. I actually encourage any beginner learning to do this kind of thing to attempt it. (I’ve learned so much!) It generally took me around 3-4 weeks or so of on and off programming to pull this thing together with the encryption logic, back-end, and database services.
In reality, your standard industry URL shortener consists of 3 main parts:
- User gives your server a link. You can decide whether or not you would like to sanitize this link. I highly recommend doing so, to some degree.
- The link is coupled with a randomized token used for the shortened URL, something along the lines of:
exam.pl/5x3sQ. This information is stored in a database. - When an external user makes a GET request to your web server using the above shortened URL token, the server simply redirects them to stored URL in their database, most of the time using a simple 302 redirect.
Already from this small list, you can see where privacy concerns start to be raised. When the link is generated, if the shortening service offers no protection, all destination links could potentially be stored as plain-text in the database. During link creation, information about who created the link, when, where, and potentially why could be determined from this simple action. Now that the link is created and stored, if a malicious external actor accesses the database, there’s even more that could be gleaned from this: as soon as a user hits the redirecting page, marketing / sale analytics, click counts, user location, IP addresses, anything and everything that can be collected will be collected. Then as the user’s final wave goodbye, if the server is performing native 30X redirects, then the host already knows where the destination is and will more than likely log who accessed those links as successfully redirected agents. This entire process and exactly where you’re attempting to navigate to will be known by the server. To make matters even worse, the company will then sell this raw analytics information back to the users of their service at a subscription price to create more of these links…
I just want to visit public websites without marketing companies making money off my traffic.
Think about how this affects someone trying to share important contact information online or via social media, with post character limits, and only a select few decentralized people needing to know? What if you want to ensure those who visit your site won’t be preyed upon by a 3rd-party when using a shortening service? What if you’re a creator that would like to distribute your content while being ‘hidden in plain sight’ utilizing some privacy protection?
This is the basic foundation that this project is built on, to strive to build something that allows privacy, protection, and anonymity. Let’s start to take a dive into what a project like this looks like. Squrl is actually an open-source software that you can use for your needs! Or maybe just to see how something like this works. Just keep in mind that the license is GPL-3.
Squrl was created using the MERN stack as a way to guide me through React and Mongo. This was my first ‘big’ CRUD project I’m pushing to prod and I thought this would be a great way to start. Mongo has been a blast to work with, and definitely prefer this document-based NoSQL schema rather than your standard SQL database. I also took this as a great opportunity to learn Tailwind to see what that was like, and I actually really enjoy it! I think I’ll end up using it on future projects going forward.
Taking what we know above with how a normal URL shortener works, let’s see how the overall design of this project approaches this.
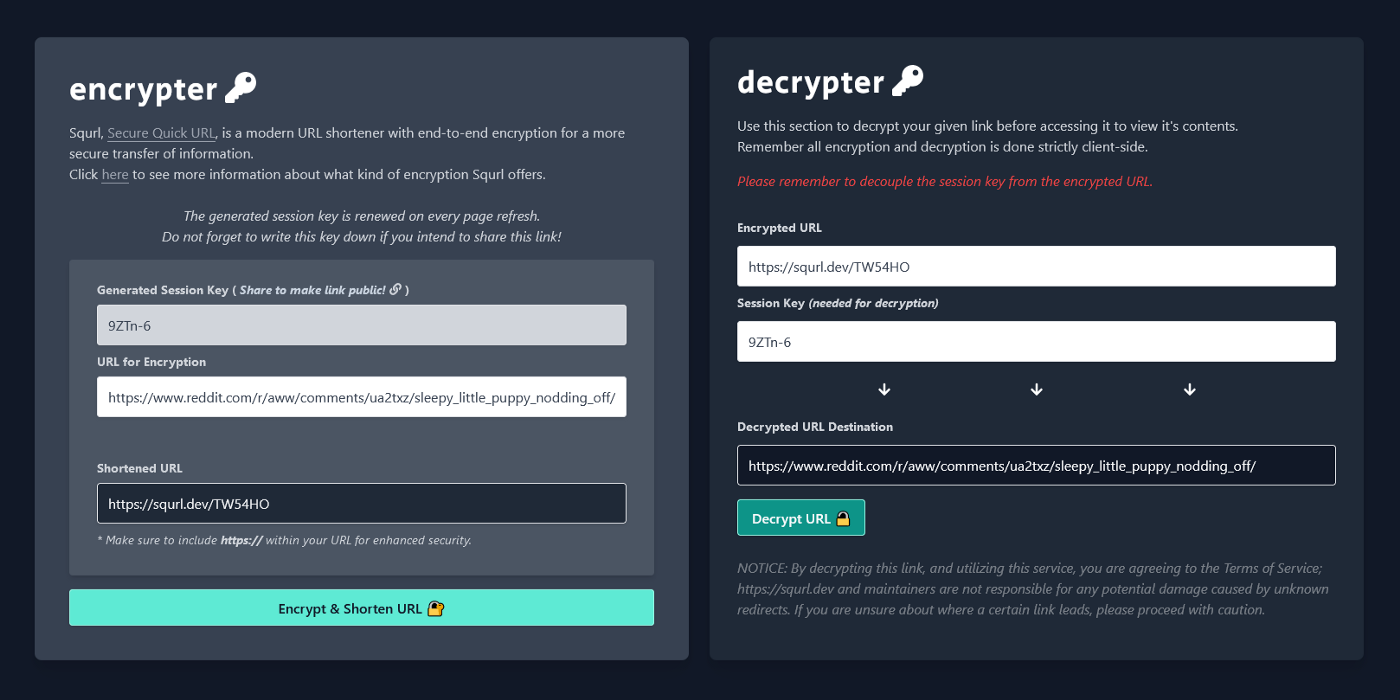
When Squrl receives a link, there are couple of things that happen to ensure proper end-to-end encryption. To start, the webpage utilizes HTTPS by default. One of the first things to note is that on every page refresh, the application with make a fetch request to an API endpoint on the server to generate a session key to fill an HTML field on the front-end with an entropy driven string, which is just a fancy way of creating a more secure, truly random token we can use as an offering to the server to store in our database. This portion is done server-side to verify that users cannot edit or modify the session key — and ultimately the password needed to access the public route — when attempting to encrypt the data. The server can then verify and present the key to the user. Thankfully, this key is just the ‘password’ used to access the encrypted data and does not map the contents. With that randomly generated sessionKey, we can then pass it into our parseUrl(sessionKey) function to begin encrypting our data!
We make sure that the link supplied by the user is actually a valid Web URI and make sure the length of the URI is below 2083 characters. That is the maximum URL length limit for Internet Explorer and Edge. While this the maximum length for URLs, contrary to RFC 2616 may want to say, this is also the same length limit for Squrl’s URIs. This limit is also mainly to reduce the potential for exceeding the MongoDB’s BSON document size of 16MB per file. I kept the ability to parse URIs instead of just standard URLs so that these may be used for application links or server related URI calls. In the end, there is no necessary need to verify if the URI was modified prior to submission or not. This sanitized string will be UTF-8 encoded during encryption anyways, and I’ll leave it up to the user whether or not to really force encrypt a piece of useless data. I may end up bridging this application with one of my own back-end projects in the future. 😉 All URLs are URIs, but not all URIs are URLs. From this part forward, I’ll just keep it simple and reference all URIs as simply “links”. Once these validations are made, parseUrl(sessionKey) then makes a fetch request to the /generate-url endpoint passing along the session key and plain-text link to attempt the encryption step.
Encrypting Data
Now we get to the meat of this article: the encryption of the link into the database, the definition of this project. As a brief overview, this is a flowchart I made detailing how it works, which takes place when a verified request reaches the /generate-url endpoint:
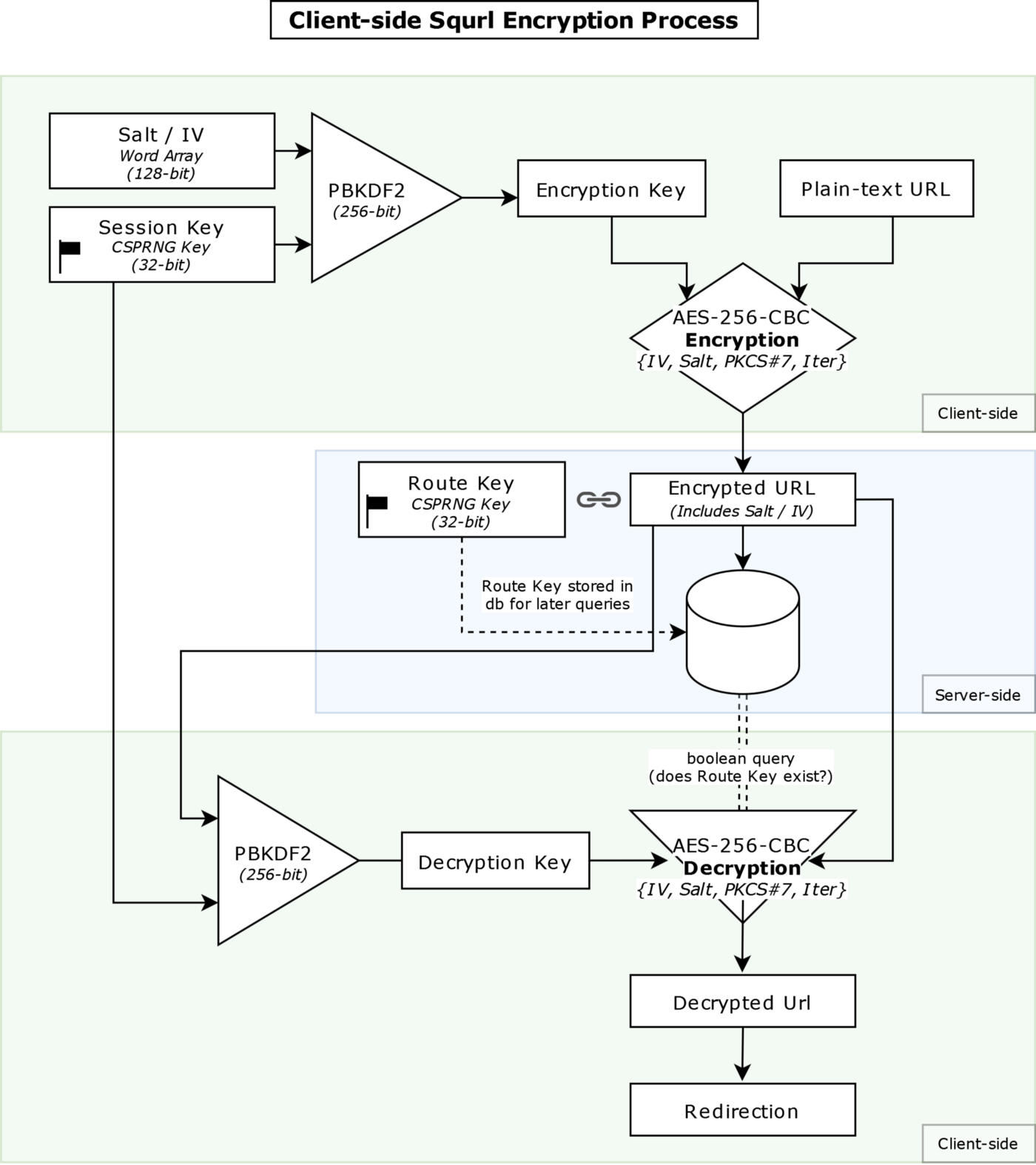
Here are the following steps that occur when encrypting the received link information (dbinteract.js):
- Using entropy, a CSPRNG produces a randomized 32-bit session key and is represented as a secret ‘password’ for the upcoming key derivation function. (and as a way to access the protected contents of a Squrl link!)
- Two randomized 128-bit word arrays are generated to comprise both the salt and IV for the initial shared encryption steps for both the encryption and decryption functions. Note: these need to remain the same on both ends to maintain an accurate exchange of information.
- The salt, IV, and session key are then both fed into a PBKDF2 hashing algorithm to generate a hashed key.
- The hashed key and plain-text link are then fed into the AES-256-CBC encryption algorithm to generate the final encrypted link to be stored in the database on the client-side. *
- Alongside the encrypted link, another 32-bit CSPRNG generated key is produced and compared to the current URL route that points to the location of the database entry after verifying it doesn’t exist to upload the final document to the database. This is the public URL token for the redirect.
* = The stored encrypted data also contains the salt and IV embedded into it for easy access in the decryption function.
Once the server verifies everything and successfully inserts the document into the database, we end up with a string pointing to the encrypted link that should look something like: https://squrl.dev/Te-K26 which then can be shortened to squrl.dev/Te-K26 if your back-end’s DNS records support setting up a naked domain — which would make sense given that this is a URL shortening service.
Database Entries
With the link now stored in the database, let’s take a look at what kind of data is actually stored in the server! After all, the entire point of this project is to be transparent, right?

When a link is encrypted and stored, the goal is to get the user to where they need to go while also maintaining the absolute LEAST amount of data possible on that user. After all, anonymity is also a core tenant of this project.
In reality, there are only basically 2 things that are crucially needed to make Squrl work: urlRoute and encryptedUrl . These two make the backbone of the entire project. I also believe we’ve covered them quite extensively in the above texts, so I won’t go over them here, but we wouldn’t be able to route without those! So what are the other things? Well, we also would like to keep track of some other information when putting something out on the internet publicly.
userAgent: A common string found in browsers that provides non-identifiable information about the browser accessing the service. Thankfully, this information is not unique, and cannot be used to locate someone by this alone. Actually, this string can be whatever your heart desires if you so choose!_id: Pretty self-explanatory, acts as the database entry’s UUID.createdAt&updatedAt: Also self-explanatory, but standard database practice fields, stored in UTC.__v: A field generated by Mongoose, relating to the document’s version key. Essentially the document’s internal revision status.
This is all the information that is known by the server. The rest is a mystery! (purposefully, of course…)
Encrypted Links! Yay! Now what?…
Great! So you go to your web browser, you input the new fancy Squrl link you just generated, squrl.dev/Te-K26, you press enter, and it seems that you’ve been greeted with a screen asking for a password instead of your preferred destination. Wait a minute… I thought this would redirect me? After all, isn’t that what this project is about?! …
Yes, but this is simply a feature of the encryption on the supplied link. Squrl actually requires two parameters in every request in order to successfully ‘authenticate’ to the server. One is the shortened URL, which becomes bound as the public link, and the other is the secret ‘password’ — the session key — that is required to successfully gain access to the link and be redirected to the right location. Using the example above, we can type in: squrl.dev/Te-K26**+**3dvQ_2, indicating both the public route and session key with a plus sign in the middle (+) — assuming they are compatible — this would become the valid ‘golden’ link that would lead to a successful redirection! If an external user attempts to navigate to a public route with no session key supplied in the link, they will be directed to the page asking for them to input the correct password to gain access.
Great! Link encrypted! Now we need to make sure people can get to where they need to be after receiving an encrypted link, but first, let’s take a look at the password screen that prompted if users do not supply a valid session key.
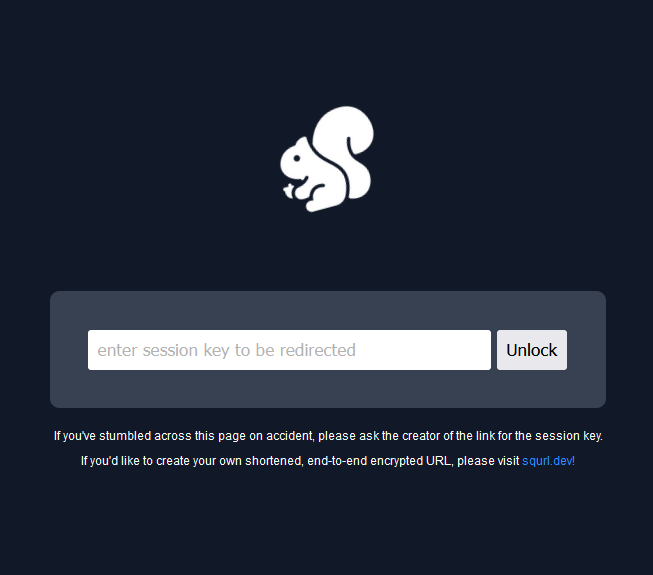
Password Screen
When attempting to access a link that users do not have access to, or simply by not supplying the session key with the public URL route, e.g. navigating to squrl.dev/Te-K26, users will be redirected to the password.ejs file where they’ll be given the opportunity to supply the known ‘password’ information to be correctly redirected to the appropriate secure location.
This primarily allows users to share the link to others inconspicuously in an open forum, publicly, while also being secure. Although, it will be the link generator’s responsibility to make sure the session key is not given to the public! (If they so choose, of course. Some links are meant to be public!)
Decrypting Data & Redirection
The decryption process is ultimately (as you’d expect) the encryption process but reversed. Various checks are performed prior to receiving the encrypted URL from the server, such as verifying the right URL route and session key were provided while making a query to the database. Once those are confirmed, the server will send the redirector.ejs file to those who accurately supply the correct link route and session key. This file is a client-side decryptor that provides the final redirection of the content.
You may have noticed that the redirector file actually ends in .ejs! Isn’t that extension commonly used in server-side rendering? Which means that this actually isn’t 100% end-to-end client-side encryption!?…
No, actually, EJS is simply a template language built to allow embedded dynamic JavaScript within HTML. A way to pass (inject) template variables and information into HTML without having to specifically hard-code what goes where. This allows us to tell the server to serve dynamic HTML that will include the encrypted URL and the session key that's needed. This is not rendered server-side, this is simply placed into the template and served directly to the user without being compiled on the server. The server still does not know where the user is heading, they are simply giving them the ‘keys’ and the ‘map’ and telling the user where to go and how to get there.
Taking a look at the redirector.ejs file, we can see where the template is applied within the decryption function:
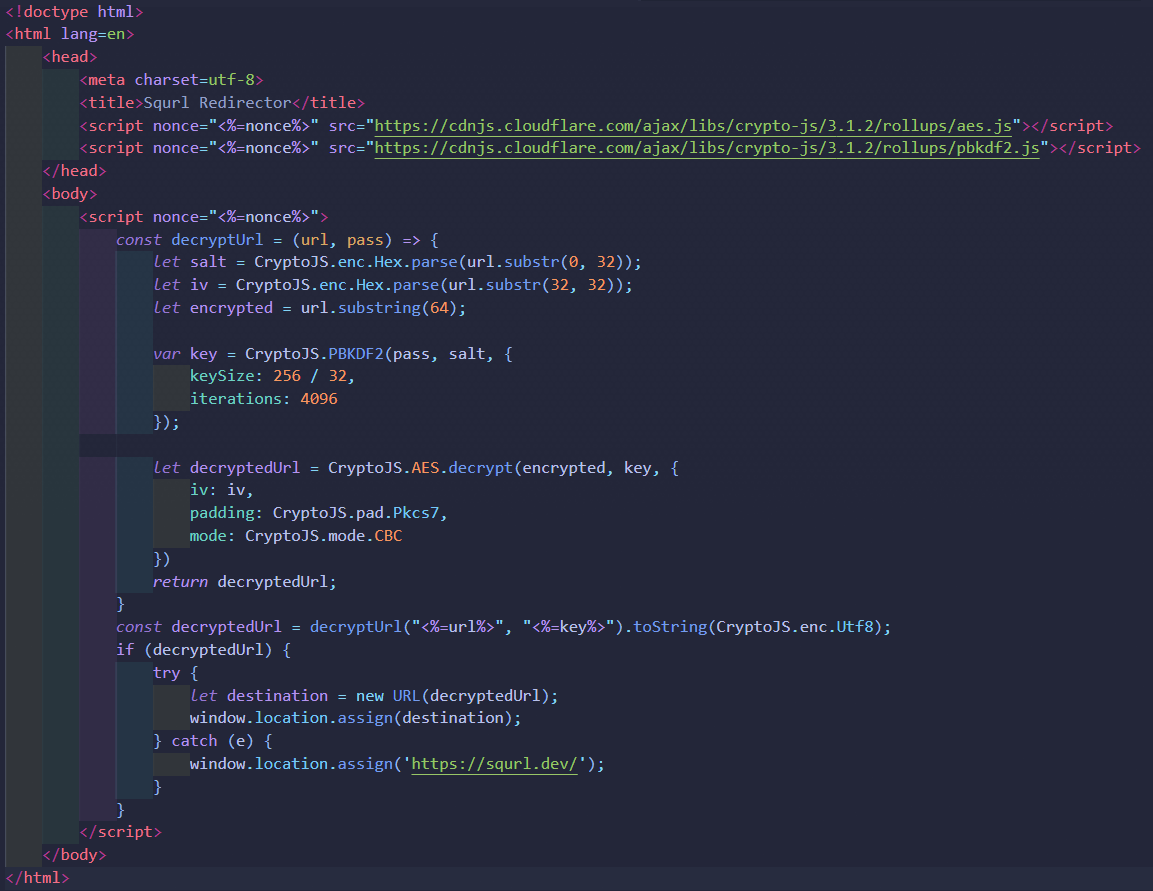
The <%=url%> and <%=key%> are the EJS injection points which simply load the encrypted URL and the session key needed for the decryption function and served to the client. Lets actually take a look at how the decryption function works:
- Inject the encrypted URL and session key into decryption function.
- The PBKDF2 function is performed again, using the same session key, IV, and salt (spliced from the encrypted source URL, remember how the salt and IV are embedded into the data), to generate an exact copy of the original hashed key used in the original encryption function.
- The actual encrypted URL data is then fed into the client-side decryption function, alongside the hashed key, to generate the fully decrypted URL output using the ‘authenticated’ (public route and session key) encrypted data queried from the database.
- The local browser client performs a
window.location.assignredirect, instead of your classic 30X redirect from the server.
You may also see that a <%=nonce%> is applied in a couple places, this is used to avoid using the unsafe-inline directive while managing your Content Security Policy. This basically only allows the browser’s CSP to run code that only contains the nonce and nothing else, to prevent Replay Attacks.
Wrapping Up
And that’s it! That’s really all it takes to create an encrypted URL shortening service. Users can continue to encrypt all sorts of URI/URL data using this service, and the database will never know what goes where, and especially who goes where.
This application was setup and configured in a Digital Ocean Droplet utilizing Express’s HTTPS server and a Let’s Encrypt SSL certificate. I’m currently managing the back-end myself; running patches and updates. Let me know in the comments if you’d like to see another post about setting something like this up for all my back-end folks using Express.
If you have any questions or concerns, please feel free to open up an issue within the repository. Submitting a PR is also greatly appreciated if you’d like to contribute or fix any issues. I hope to be sharing more project breakdowns here soon. Thanks for reading!