Darkness Awaits: How I Built My MongoDB-Powered Next.js Site to Store Dark Wallpapers
My name is Justin! 👋 I am a hobbyist and freelancing Full Stack Developer using Next.js & TypeScript who designs games sometimes. 😎
Currently: Learning anything and everything I can about supporting scalable server applications and gorgeous frontends!
💼 Over 8 years working in IT
💻 Full Stack (Next.js/Typescript/MongoDB)
🎓 B.S. in Cybersecurity & Information Assurance
🎗️ Multiple IT certifications and skillsets
🕹️ Founded a local game design studio in Dallas, TX
I'm open to full stack, fully remote positions! Please get in contact.
Like most people, I am not a fan of Light Mode. That may seem like heresy to some, but I digress; I need to use dark themes for almost everything I do that involves my computer to help my eyes.
One of the main things that I've struggled with over the past few years is finding good dark-themed, landscape wallpapers. There are some here and there that I love, but once I find a few that I like, holding onto them gets hard over time, so I wanted to start a project that would resolve this issue for me.
Introducing Umbraeus
Umbraeus (Uhm-bray-us) is now another project I recently created over a week or two and introduced into my portfolio that I would love to share with you.
It's an infinite-scrolling, full-stack image gallery using an API to upload and fetch images held within a MongoDB instance storing links to great dark-themed, landscape wallpapers.
Demo
Stack
The main website, and what the majority of this article is about, is built on the following stack:
Next.js / React
TypeScript
MongoDB (Atlas)
Deployed with:
Vercel
Imgur
UmbraVault, described later on in the article, was built in simply Node.js.
Project Layout
I knew from the start that this project was not going to be complicated. I just wanted a singular, online repository that I could use to store any landscape wallpapers that I find that I know I would potentially want to use again someday.
Yes, I could technically just download them directly and manually host them somewhere, but I wanted to be able to also share this project with other people online, and I definitely didn't want to host large-format (2k - 8k+) images myself in a personal cloud or local storage option. I needed to find a way to host the images I needed almost completely autonomously and pretty cheaply.
Imgur
As a preface to the database workflow, Imgur does technically allow you to upload to its CDN for free, as long as you have a valid API key, and you intend to post content to Imgur directly that revolves around discussion, upvotes, etc., but it is explicitly against their TOS to hotlink images from their website to use as content within your website, unless you are specifically paying for the paid API.
Imgur's CDN is a globally distributed network of servers that are optimized for delivering images and videos at high speed. When you upload an image to Imgur, it is automatically stored on their CDN and served to users from the server location that is closest to them. It greatly eliminates the need for slow load times and means that users can enjoy dark-themed wallpapers quickly, no matter where they are located in the world.
MongoDB
I won't go into minute detail about setting up and configuring the MongoDB Atlas instance, there are tons of resources online about doing this, even directly from the MongoDB developers themselves, but it is very straightforward.
Just know that I am not hosting the database locally, and MongoDB offers a great, free tier that utilizes 512Mb of cloud storage alongside shared memory and processor usage with the rest of the free tier Atlas community. This is perfect for our needs! We'll take the image links that are provided by Imgur's API and can host the raw string data in our free MongoDB cluster.
Within Atlas, I simply created a table that was called Wallpapers, which I could use to start storing documents in it using a simple schema that looked something like this to begin processing against the database. This schema was integrated with Mongoose:
const wallpaperSchema = new Schema<wallpaper>(
{
src: String,
alt: String,
author: String,
title: String,
views: Number,
likes: Number,
downloads: Number,
resolution: {
width: Number,
height: Number,
},
softDelete: Boolean,
},
{ timestamps: true }
);
This schema contains basic information about what is needed to render the images, but I also included some other fields that I may utilize in the future, such as views, likes, downloads, and softDelete. Note that these data types are not TypeScript data types, rather they are MongoDB-specific types.
For now, we only need the src of the image, the author, title, and alt text to fill the front-end with information related to our images.
UmbraVault
We have our wallpapers, database, and CDN; we can get started! Before we do though, it has become a pain to get these beloved images into the database efficiently.
There is another project that I created in conjunction with this one, UmbraVault, which is a DevOps tool that I use to remotely apply CRUD operations to the MongoDB instance. I used to manually make POST requests to the API endpoint using something like Postman, or use the Atlas website/CLI, but I've decided that if this is going to be a more long-term project, I should probably create custom tooling. This tool alone improved my upload process drastically, and now I see myself creating accompanying internal tools all the time like this in the future!
Here's how it works: by supplying an input folder of images -i and an output folder -o, you are asked some questions about the content and size of the image in question. The script makes a POST request to the Imgur API and uploads the image. The link to the uploaded image is then returned and supplied as the source URL for the database entry following the questions the script will ask you. The final step is the information supplied in the schema object is stored in the database as a MongoDB document. Then the script just loops back to the start and asks about uploading another image.
For "garbage collection", we simply pick up the image and move it into the output folder specified. It's an easy way to understand which images have been uploaded to the database and which haven't.
UmbraVault is built on the inquirer package to allow the custom inputs to ask questions about the image metadata that is needed to get uploaded into the database. Another package, inquirer-autocomplete-prompt, is used to list the filenames from the respective input folders, and will update the autocomplete list as you type!
With this workflow, I can upload upwards of 15-20 images in around 15 minutes, depending on the content. The time constraint here is that all alt-text information and titles that are listed are created by me unless otherwise specified from the image source. Though, a majority of these images were obtained royalty-free, with permission, from Unsplash, which comes mostly untitled and only supplies a few tags. This means I spend a couple of minutes sometimes thinking about a title or alt-text for some 😅 but if the titles were pre-written, technically it would be possible to conduct a large import via JSON or CSV into the database and upload images almost instantly.
Component Tree
The overview of the project is extremely simple, there are only a few React components that are needed to get the front-end up and running:
<App>
<Lightbox /> // Lightbox expands selected images
<Umbraeus /> // Umbraeus displays queried images
</App>
<App /> of course is the main instance of Next.js that is running the overall wrapping structure, while the <Umbraeus /> component is filling the page with the appropriate images received from the database as the user continually scrolls down the page. The <Lightbox /> component just enlarges whatever picture was selected so that it may be right-clicked and Set As Background or saved locally. This component in particular is conditionally rendered.
In this article, we're going to focus on just the two main components, <Umbraeus /> and <Lightbox />.
Umbraeus Component
When the page first loads, an API call will be made to the back-end of Next.js to query the database and begin pulling in images. We do this with a simple fetch to the /api/ route along with some React state and then append the images that we received to the end of the images array we already have:
const [pageNumber, setPageNumber] = useState(1);
const loadImages = (page: number) => {
setLoading(true);
fetch(`/api/queryWallpapers?page=${page}`)
.then((response) => response.json())
.then((data) => {
if (data.documents) {
setImages((prevImages) => [
...prevImages,
...data.documents,
]);
setLoading(false);
}
})
.catch((error) => {
console.error(error);
setLoading(false);
});
};
Here, we call /api/queryWallpapers and we pass in the page parameter through the URL to give the server an idea of exactly what page we'd like to query to receive images from and append to our component. We don't want all the images every time we fetch data, as at some point there could be hundreds or even thousands! That would be inefficient! Instead, we'll paginate the results and only query what we need, when we need it.
After verifying the API request is valid and okay, the default response is 16 images pulled from the database. We do that with the following code from within the API:
const page = Number(req.query.page) || 1;
const perPage = 16;
const startIndex = (page - 1) * perPage;
try {
const totalDocuments = await Wallpaper.countDocuments();
const totalPages = Math.ceil(totalDocuments / perPage);
if (page > totalPages) {
// Return empty response for invalid page number
return res.status(200).json({ documents: [], totalPages });
}
const documents = await Wallpaper.find()
.skip(startIndex)
.limit(perPage)
.sort({ _id: -1 }) // newest first
.exec();
return res.status(200).json({ documents, totalPages });
} catch (error) {
console.error(error);
return res.status(500).json({ message: 'Something went wrong.' });
}
We gather the
pageparam from the URL query, or substitute it with 1 if there isn't one provided, and initialize the rest of our variables, including ourstartIndexfor our paginated results.We'll count the total number of documents, and we'll create a new
totalPagesvariable dividing thetotalDocuments / perPage (16)and rounding up to determine how many times we can query wallpapers for pages.- If we're out of bounds in our pages, we'll only return an empty array with extraneous information.
Perform an asynchronous query to the Wallpaper MongoDB instance to find all current documents,
skipover the images that have already been requested,limitthe number of images that can be returned,sortthe documents by their Mongo_idfield against-1, which is a descending order (newest uploaded first), and then finally weexecthe final query to execute it, which returns a Promise of the Wallpaper results!
We then take these fancy results, stored in images, and run them through a map function, which will iterate over the images array and create individual <BackgroundImage /> components, which is a Mantine component, for each result. (See below) Filling the interior component information with the newly mapped image array and rendering those appropriately only on prop change. (more on that later!)
💡At some point in the future, each image should be extrapolated and wrapped in its own separate component file, but for now, this is the main focal point for <Umbraeus />.
{images.map((image: wallpaper) => (
<div
key={image._id}
className={styles.wrapper}
onClick={() => setSelectedImage(image)}
>
<BackgroundImage
className={styles.image}
src={regulateResolution(image.src, 'l')}
>
<Stack className={`${styles.fade} ${styles.image_stack}`} p={10} justify={'space-between'}>
<Text size={'sm'} align="right">{`${image.resolution.width}x${image.resolution.height}`}
</Text>
<Stack>
<Text size={'sm'} className={styles.author}>
{image.author}
</Text>
<Text size={'lg'}>{image.title}</Text>
</Stack>
</Stack>
</BackgroundImage>
</div>
))}
For the source of the wallpaper image to display, we should not be using the original full-size image that we have access to. Some of these 8K images could potentially be 50+ megabytes in size, which would be detrimental to load times!
Instead, the function regulateResolution(source, suffix) gets called to make sure we're being performant with our media. This is mostly the Imgur CDN doing the heavy lifting, but it's on us as developers to do our due diligence.
// Strictly for Imgur related URL requests.
const regulateResolution = (str: string, suffix: string): string => {
const lastPeriodIndex = str.lastIndexOf('.');
if (lastPeriodIndex === -1) {
return str;
} else {
return (
str.slice(0, lastPeriodIndex) +
suffix +
str.slice(lastPeriodIndex)
);
}
};
Imgur understands performant media as well, and as such, can use downscaled versions of media uploaded to their systems. We take in the source image, and preferred size suffix. It will just find the last period, splice it, append the letter then stitch it back together. This will become our preferred source URL. This could be extended in the future to lower resolution dynamically if preferred, potentially on mobile devices.
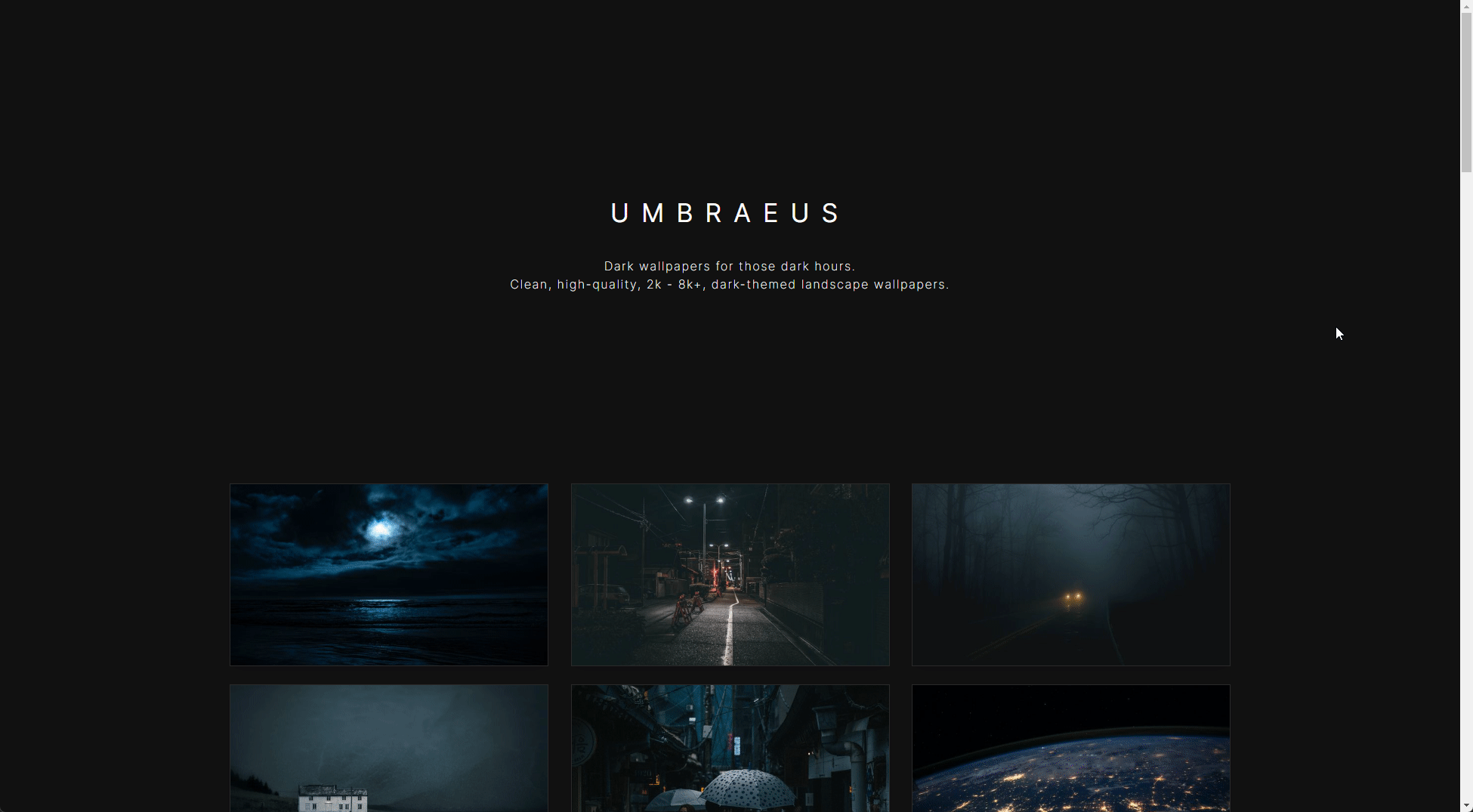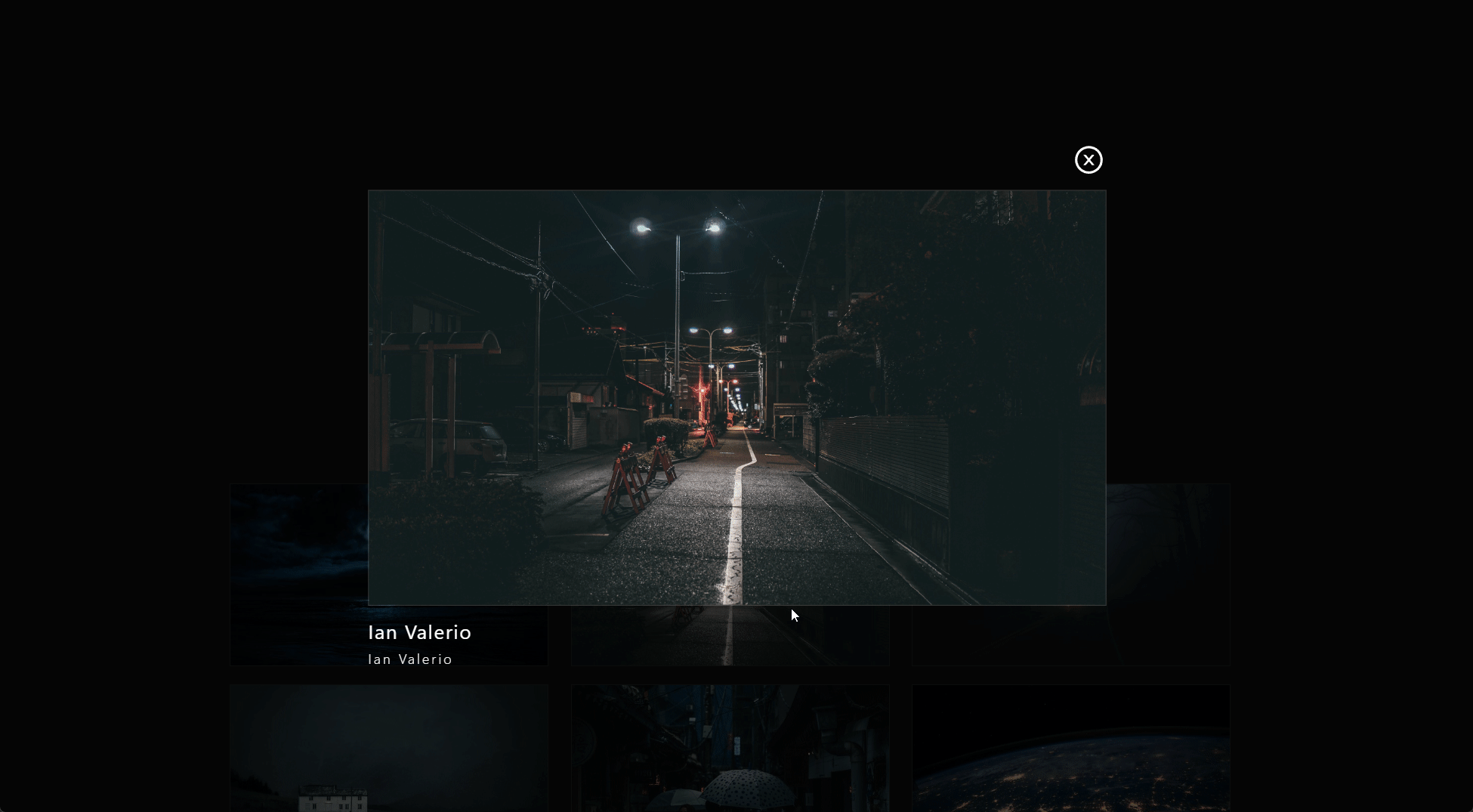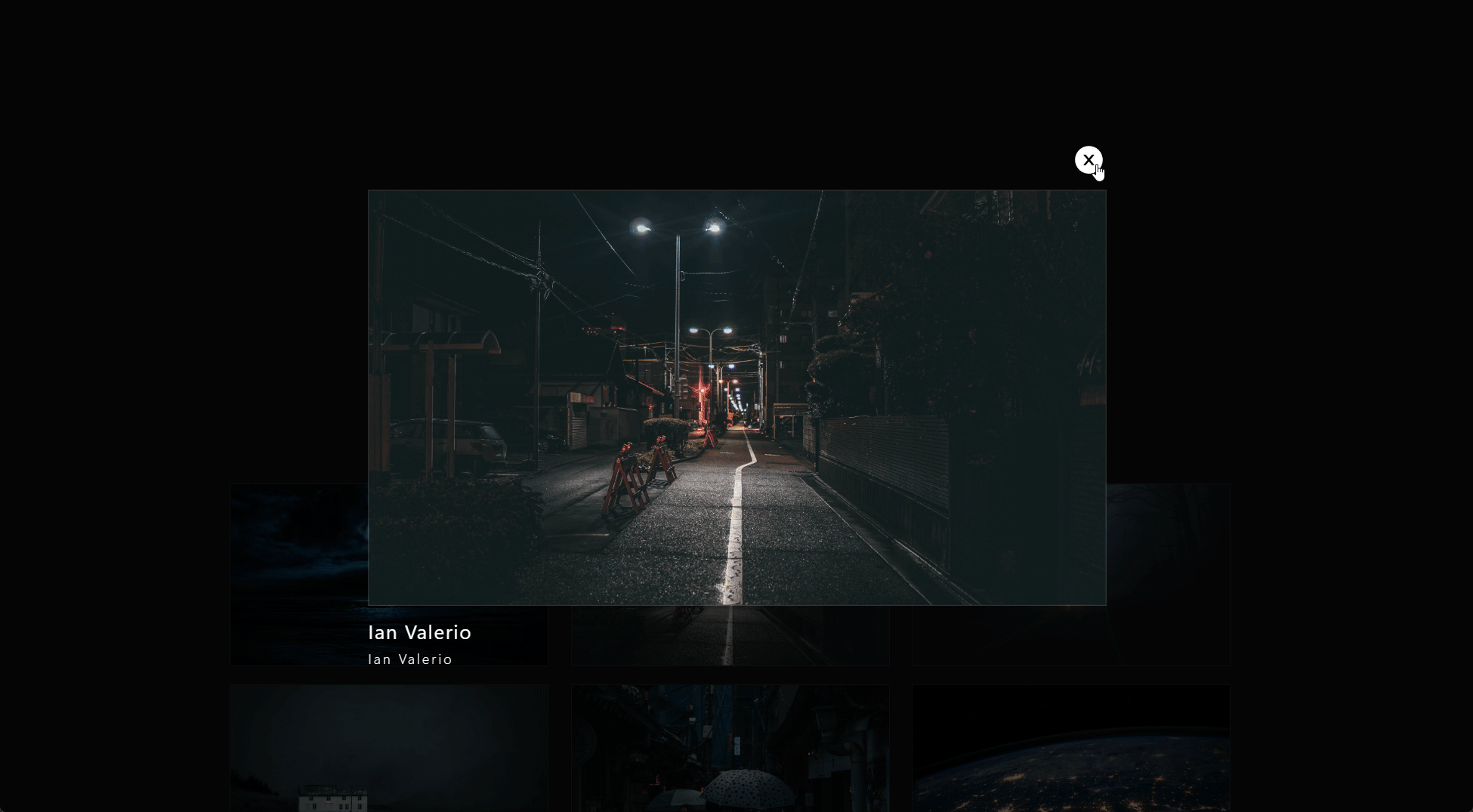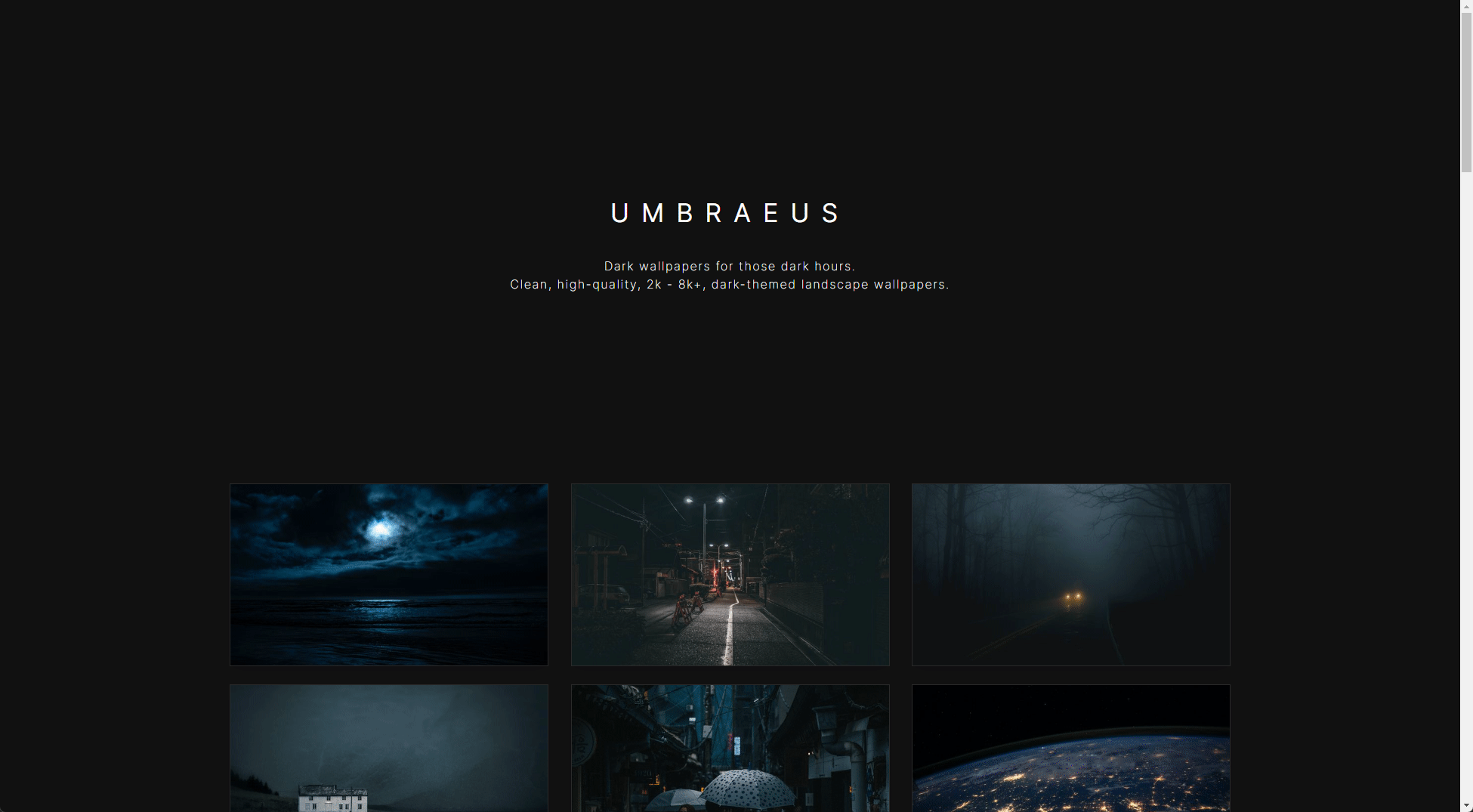
The images are then stacked in a simple grid and displayed to the user. Below is a GIF of those image components in action. Load times are great for these 16 images (9 shown) and thankfully the page finishes loading in under 1 second! (The power of distributed CDN nodes and manageable file sizes!)


This is great and all, but how do we get more images to load?
Currently, this is only spitting out a few images and we're not doing anything related to future paginated results. Let's change that.
Still in our <Umbraeus /> component, we can create a new function called handleScroll().
const handleScroll = () => {
const { scrollTop, scrollHeight, clientHeight } =
document.documentElement;
if (scrollTop + clientHeight >= scrollHeight - 300 && !loading) {
setPageNumber((prevPageNumber) => prevPageNumber + 1);
}
};
We need a way to have the browser understand that we have reached the bottom area of the webpage and need to acquire more images for the feed. This will take the browser's document property and destructure the variables we need to help us implement this infinite-scrolling. We do some calculations with the browsers height and the total length scrolled, offset it by any number we specify (300), verify we aren't already loading something, if not, let's go ahead and increment our page number, thus prompting a simple useEffect(() => {...}, [pageNumber]) hook to re-call the /api/queryWallpapers endpoint and start the entire process over again!
We need. more. IMAGES.

This scroll handling function can then be bound to our 'scroll' event listener to always verify how close we are to the bottom.
window.addEventListener('scroll', handleScroll);
And there we have it! An infinite-scrolling selection of wallpapers at our disposal! As long as we continually fill up the database with metadata related to the wallpapers, users can continue to scroll until they finally reach the end.
(Keep in mind, running React in strict-mode causes some initial component re-renders only at the start. In production, this extra render does not exist, so images won't be duplicated.)

Lightbox Component
The <Lightbox /> component is very straightforward. Some React state is set whether or not to show the lightbox and another is to lock the ability for the scroll wheel to be used. useScrollLock() is a custom Mantine Hook, that was available in v5.10.5. It doesn't seem to exist in v6.0, but it may have been moved or consolidated into another hook.
Once the user clicks on an image, setVisible(true) is called, which prompts the useEffect() hook below to toggle the setLockState(). Once called, and the lightbox is visible, the image is displayed at full resolution front and center.
const [visible, setVisible] = useState(true);
const [scrollLock, setLockState] = useScrollLock(false);
useEffect(() => {
setLockState((c) => !c);
}, [visible]);
To make the lightbox disappear. we simply set the setLightbox(false) state value to close the lightbox anytime the X button in the top-right is clicked.
Conclusion
That's it! You have your own, cloud-based dark wallpaper database collection showcased in a nice, infinite-scrolling gallery! 🥳🎉
In the end, this was just a simple project for my portfolio that didn't take too long, thankfully. I don't think I would scale this up to anything reasonable. This may get its own domain name at some point, but I'm not entirely sure. I may come back in the future to use this as a jumping-off point for future projects or more ideas.
For now, I'll slowly continue to upload wallpapers that I love and that don't hurt my eyes, and if you just happen to bookmark that page, you'll have them too. 💖 If you managed to scroll past it, the demo is towards the top. Take a look around, and let me know what you think!
Wishlist
This is just a small list of things that would make great additions to this project later:
Lazy Loading / Skeleton Images
Complex Filtering / Search Bar
Public Likes, Views, Comments, Download Info
Hashing / Duplicate Detection
Better CSS / Styling Update
More Animations (Fading, Slides, Etc.)
Thanks for stopping by! If you want to keep reading about more projects like this, or about the weird tools that I build as well, then give me a follow on Hashnode, or subscribe to my newsletter to stay up to date on when I publish!
Thanks!



