Writing a Simple Command-Line Wrapper for OpenAI's API

My name is Justin! 👋 I am a hobbyist and freelancing Full Stack Developer using Next.js & TypeScript who designs games sometimes. 😎
Currently: Learning anything and everything I can about supporting scalable server applications and gorgeous frontends!
💼 Over 8 years working in IT
💻 Full Stack (Next.js/Typescript/MongoDB)
🎓 B.S. in Cybersecurity & Information Assurance
🎗️ Multiple IT certifications and skillsets
🕹️ Founded a local game design studio in Dallas, TX
I'm open to full stack, fully remote positions! Please get in contact.
Artificial Intelligence will be playing a big role in technology within the next few decades. We are already seeing the monumental shift and impact they are currently producing, with debate on applications such as GitHub's Copilot or Stable Diffusion, with a plethora of other tools and companies now expanding into every booming market of artificially generated things.
In a recent blog post, I wrote about training OpenAI's most advanced natural language processing model, GPT-3, on generating new ideas and concepts for SaaS products. I highly recommend giving it a read if you're interested in what the future holds. If you take a look at the cover image for this article, asking an AI the recipe for a twice-baked potato was a very important milestone for me, I just had to expand this concept even more.
It's actually what I had for dinner tonight. Thank you, AI! 🍴🥔♨️
Spark of an Idea💡
This article is somewhat a continuation of that. I was having so much fun generating new things, I just went ahead and created a whole new project to be able to quickly query GPT-3 without having to go back and edit my scripts over and over again.
Please note: this was just a little project for me to spend my Sunday afternoon. You can probably get more done using the Playground that OpenAI offers, which basically is a pre-made frontend for all of these commands, the API, and more!
This article will be fairly quick, I just wanted to braindump my thoughts on going into this project. You can actually view the entire repository here on GitHub. I welcome any Pull Requests or Issues opening on the project. I'll review or reply to whatever I can if it's worth attending to.
Package Stack 💻
Thankfully, this project is not complicated, there are just a couple of core systems at play here:
openai-nodecommanderwinston
Two of these packages are some of my favorite of all time: winston and commander. Winston is a logging framework that has been designed to make logging to multiple endpoints and in multiple formats very easy. I believe with this project included, I've used Winston on almost all my node-based/backend projects. It's great, I highly recommend using this instead of console.log()ing anything and everything. For example, all queries to GPT-3 are run through a custom format that is basically just an export of the response directly to a file.
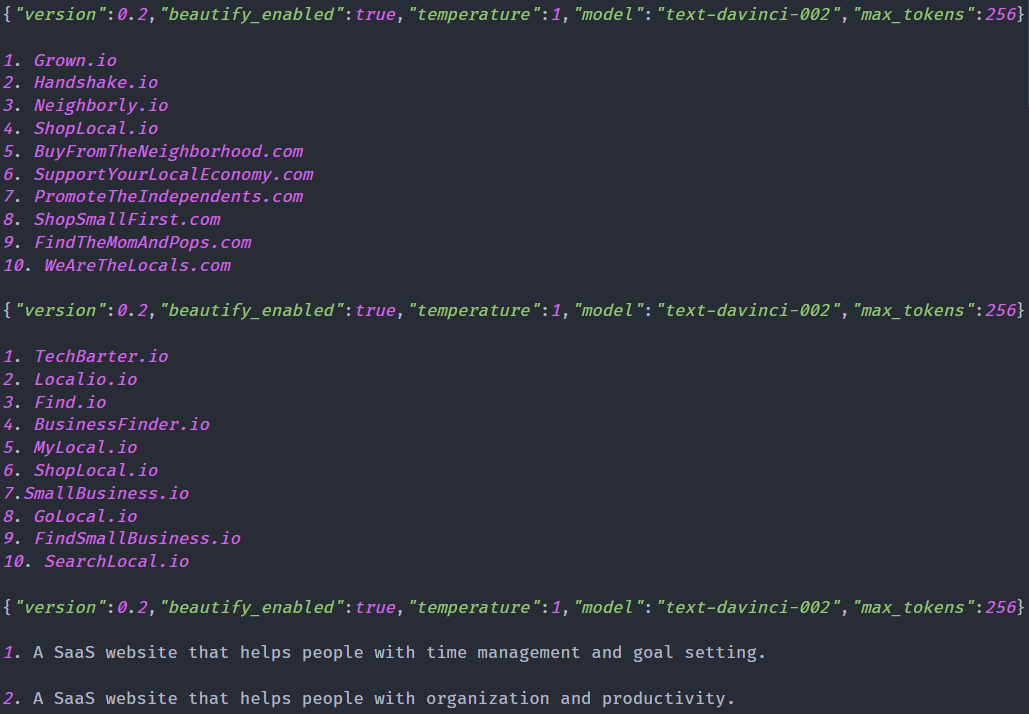
Commander on the other hand is what I am currently using for parsing my flags and arguments that are being passed to GPT-3. I have no preference really on what to use for this, I've tried yargs and I've been informed about argparse from other people, but have only really used Commander. It's great, I love it. It's very simple and easy to setup flags that can be customized and configured to my liking.
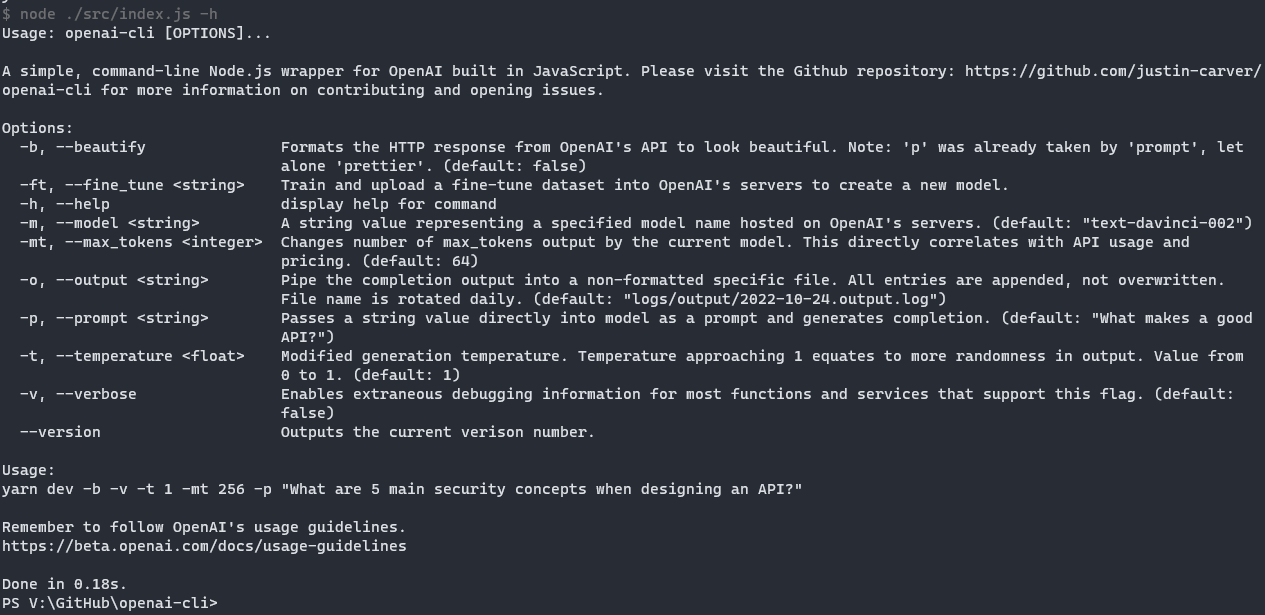
I was also very impressed that the --help flag is automatically generated and populated based on the commands that have been configured for it.
Code Breakdown 🛠️
It's really only two functions at the moment, but I'm surprised that Commander picked up most of the weight for the CLI functionality. At the moment it's very simple, a simple wrapper (as the titles states), but I'd love to expand on this later, maybe even introduce subcommands or native piping.
This is the main function. It parses arguments from the ./lib/utils.js file that I've sectioned off to hold the arguments and Winston functions to clear up some of the space in the project. We just check to see if any of the flags are present, if so, we'll run some functions based on their status or trigger. If you want to see more of the second function in action, the fine-tune model function is a core part of my previous article linked above! Check it out! 💖
const main = async () => {
const vObj = {
version: 0.2,
beautify_enabled: options.beautify,
temperature: parseInt(options.temperature),
model: `${options.model}`,
max_tokens: parseInt(options.max_tokens),
};
// Please refer to ./lib/utils for more information on arguments.
if (options.output) {
winstonAddFileTransport(options.output);
}
if (options.prompt) {
const response = await openai.createCompletion({
model: `${options.model}`,
prompt: `${options.prompt}`,
temperature: parseInt(options.temperature),
max_tokens: options.max_tokens ? parseInt(options.max_tokens) : 64,
});
options.verbose ? logger.info(JSON.stringify(vObj)) : null;
options.beautify
? logger.info(beautify(response.data.choices[0].text))
: logger.info(JSON.stringify(response.data.choices));
} else {
logger.error('No prompt was supplied. API force quit.');
}
// ? Remember! Fine-tuning can be pricey!
if (options.fine_tune) {
trainFineTuneModel(options.fine_tune);
}
};
main();
And that's it! Now I can continually query GPT-3 from the command line, if necessary. Change a ton of attributes on the fly, and see what combination generates the best output! This could also be an interesting concept if one was potentially locked to a terminal only environment, such as being on a server or connected to a VPS hosted in the cloud.
Potentially this could be expanded to function with external scripting sources, like bash or shell scripting. 🤔 I do have some potential ideas to expand this later, including linking this with an autonomous Twitter bot to generate AI-driven social media posts, so stay tuned!
Subscribe to my newsletter above if you wish to read more about my little side projects!